📓2.1: Pandas DataFrames
Table of Contents
- What is Data Science? 🧪
- Data Manipulation with Pandas 🐼
- Pandas Objects
- Helpful
DataFrameOperations - ⭐️ Glossary
✴✴✴ NEW UNIT/SECTION! ✴✴✴
Create a blank Python program to take your class notes in for the next few lessons.
Click on the collapsed heading below for GitHub instructions ⤵
📓 NOTES PROGRAM SETUP INSTRUCTIONS
- Go to the public template repository for our class: BWL-CS Python Template
- Click the button above the list of files then select
Create a new repository - Specify the repository name:
CS3-Unit2-Notes - Click
Now you have your own personal copy of this starter code that you can always access under the
Your repositoriessection of GitHub! 📂 - Now on your repository, click and select the
Codespacestab - Click
Create Codespace on mainand wait for the environment to load, then you’re ready to code! - 📝 Take notes in this Codespace during class, writing code & comments along with the instructor.
🛑 When class ends, don’t forget to SAVE YOUR WORK! Codespaces are TEMPORARY editing environments, so you need to COMMIT changes properly in order to update the main repository for your program.
There are multiple steps to saving in GitHub Codespaces:
- Navigate to the
Source Controlmenu on the LEFT sidebar - Click the button on the LEFT menu
- Type a brief commit message at the top of the file that opens, for example:
updated main.py - Click the small
✔️checkmark in the TOP RIGHT corner - Click the button on the LEFT menu
- Finally you can close your Codespace!
What is Data Science? 🧪
- Data Science
- An emerging, interdisciplinary field that brings together ideas that have been around for years, or even centuries about processes and systems to extract knowledge and/or to make predictions from data in various forms.
In 2016 a study reported that 90% of the data in the world today has been created in the last two years alone. This is the result of the continuing acceleration of the rate at which we store data. Some estimates indicate that roughly 2.5 quintillion bytes of data are generated per day; that’s 2,500,000,000,000,000,000 bytes!
By comparison, all the data in the Library of Congress adds up to about 200 TB, merely 200,000,000,000,000 bytes. This means that we are capturing 12,500 libraries of congress per day!
The amount of data that Google alone stores in its servers is estimated to be 15 exabytes (15 followed by 18 zeros!). You can visualize 15 exabytes as a pile of cards three miles high, covering all of New England.
Everywhere you go, someone or something is collecting data about you: what you buy, what you read, where you eat, where you stay, how and when you travel, and so much more. By 2025, it is estimated that 463 exabytes of data will be created each day globally, and the entire digital universe is expected to reach 44 zettabytes by 2020. This would mean there would be 40 times more bytes than there are stars in the observable universe!
Often, this data is collected and stored with little idea about how to use it, because technology makes it so easy to capture. Other times, the data is collected quite intentionally. The big question is: what does it all mean? That’s where data science comes in.
What does a data scientist do?
As an interdisciplinary field of inquiry, data science is perfect for a liberal arts college as well as many other types of universities. Combining statistics, computer science, writing, art, and ethics, data science has application across the entire curriculum: biology, economics, management, English, history, music, pretty much everything. The best thing about data science is that the job of a data scientist seems perfectly suited to many liberal arts students.
“The best data scientists have one thing in common: unbelievable curiosity.” - D.J. Patil, Chief Data Scientist of the United States from 2015 to 2017.
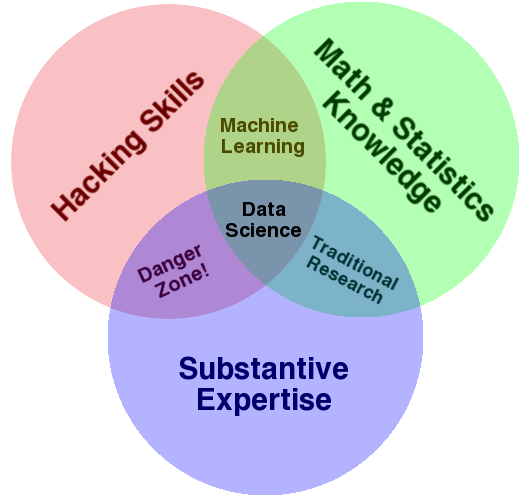
The diagram above is widely used to answer the question “What is Data Science?” It also is a great illustration of the liberal arts nature of data science. Some computer science, some statistics, and something from one of the many majors available at a liberal arts college, all of which are looking for people with data skills!
Data Manipulation with Pandas 🐼

From NumPy to Pandas
NumPy is a Python library centered around the ndarray object, which enables efficient storage and manipulation of dense typed arrays. Pandas is a newer package built on top of NumPy that provides an efficient implementation of a DataFrame, which is the main data structure offered by Pandas.
NumPy’s limitations become clear when we need more flexibility (e.g., attaching labels to data, working with missing data, etc.) and when attempting operations that do not map well to element-wise broadcasting (e.g., groupings, pivots, etc.), each of which is an important piece of analyzing the less structured data available in many forms in the world around us.
- DataFrame
- A multidimensional array object with attached
rowandcolumnlabels, often containing heterogeneous types and/or missing data. The concept is similar to a spreadsheet in Excel or Google Sheets, but more versatile.
As well as offering a convenient storage interface for labeled data, Pandas implements a number of powerful data operations familiar to users of both database frameworks and spreadsheet programs. Pandas, and in particular its Series and DataFrame objects, builds on the NumPy array structure and provides efficient access to these sorts of “data munging” tasks that occupy much of a data scientist’s time.
As we will see during the course of this chapter, Pandas provides a host of useful tools, methods, and functionality on top of the basic data structures, but nearly everything that follows will require an understanding of what these structures are. Thus, before we go any further, let’s take a look at these three fundamental Pandas data structures: the Series, DataFrame, and Index.
We will start our code sessions with the standard NumPy and Pandas imports, under the aliases np and pd:
import numpy as np
import pandas as pd
Pandas Objects
The Series Object
- Series
- A one-dimensional array object of indexed data.
A Series object can be created from a list or array as follows:
data = pd.Series([0.25, 0.5, 0.75, 1.0])
The Series combines a sequence of values with an explicit sequence of indices, which we can access with the values and index attributes. The values are simply a NumPy array:
data.values
The index is an array-like object of type pd.Index, which we’ll discuss in more detail momentarily:
data.index
Like with a NumPy array, data can be accessed by the associated index via the familiar Python square-bracket notation:
data[1]
data[1:3]
As we will see, though, the Pandas Series is much more general and flexible than the one-dimensional NumPy array that it emulates.
Series as Generalized NumPy Array
From what we’ve seen so far, the Series object may appear to be basically interchangeable with a one-dimensional NumPy array. The essential difference is that while the NumPy array has an implicitly defined integer index used to access the values, the Pandas Series has an explicitly defined index associated with the values.
This explicit index definition gives the Series object additional capabilities. For example, the index need not be an integer, but can consist of values of any desired type. So, if we wish, we can use strings as an index:
data = pd.Series([0.25, 0.5, 0.75, 1.0],
index=['a', 'b', 'c', 'd'])
print(data)
And the item access works as expected:
print(data['b'])
We can even use noncontiguous or nonsequential indices:
data = pd.Series([0.25, 0.5, 0.75, 1.0],
index=[2, 5, 3, 7])
print(data)
print(data[5])
Series as Specialized Dictionary
In this way, you can think of a Pandas Series a bit like a specialization of a Python dictionary. A dictionary is a structure that maps arbitrary keys to a set of arbitrary values, and a Series is a structure that maps typed keys to a set of typed values. This typing is important: just as the type-specific compiled code behind a NumPy array makes it more efficient than a Python list for certain operations, the type information of a Pandas Series makes it more efficient than Python dictionaries for certain operations.
The Series-as-dictionary analogy can be made even more clear by constructing a Series object directly from a Python dictionary, here the five most populous US states according to the 2020 census:
population_dict = {'California': 39538223, 'Texas': 29145505,
'Florida': 21538187, 'New York': 20201249,
'Pennsylvania': 13002700}
population = pd.Series(population_dict)
From here, typical dictionary-style item access can be performed:
print(population['California'])
Unlike a dictionary, though, the Series also supports array-style operations such as slicing:
print(population['California':'Florida'])
Constructing Series Objects
We’ve already seen a few ways of constructing a Pandas Series from scratch. All of them are some version of the following:
pd.Series(data, index=index)
where index is an optional argument, and data can be one of many entities.
For example, data can be a list or NumPy array, in which case index defaults to an integer sequence:
pd.Series([2, 4, 6])
Or data can be a scalar, which is repeated to fill the specified index:
pd.Series(5, index=[100, 200, 300])
Or it can be a dictionary, in which case index defaults to the dictionary keys:
pd.Series({2:'a', 1:'b', 3:'c'})
In each case, the index can be explicitly set to control the order or the subset of keys used:
pd.Series({2:'a', 1:'b', 3:'c'}, index=[1, 2])
The Pandas DataFrame Object
The next fundamental structure in Pandas is the DataFrame. Like the Series object discussed in the previous section, the DataFrame can be thought of either as a generalization of a NumPy array, or as a specialization of a Python dictionary. Since we didn’t spend time on NumPy arrays, we’ll focus on the concept of a DataFrame as a specialized dictionary.
DataFrame as Specialized Dictionary
Where a dictionary maps a key to a value, a DataFrame maps a column name to a Series of column data. For example, asking for the 'area' attribute returns the Series object containing the areas we saw earlier:
print(states['area'])
Constructing DataFrame Objects
A Pandas DataFrame can be constructed in a variety of ways. Here we’ll explore several examples.
From a single Series object
A DataFrame is a collection of Series objects, and a single-column DataFrame can be constructed from a single Series:
pd.DataFrame(population, columns=['population'])
From a list of dicts
Any list of dictionaries can be made into a DataFrame. Even if some keys in the dictionary are missing, Pandas will fill them in with NaN values (i.e., “Not a Number”)
We’ll use a simple list comprehension to create some data:
data = [{'a': i, 'b': 2 * i}
for i in range(3)]
pd.DataFrame(data)
From a dictionary of Series objects
As we saw before, a DataFrame can be constructed from a dictionary of Series objects as well:
pd.DataFrame({'population': population,
'area': area})
Helpful DataFrame Operations
- Download this Pokemon Dataset CSV file to use while we learn
Pandasoperations. - Upload it to your
Unit-2-Notesrepository. - Load data from the CSV file into a
DataFrame:pokemon = pd.read_csv('pokemon_data.csv') - Check out the DataFrame:
print(pokemon) print(pokemon.columns)
Selecting Columns in DataFrames
Recall that a DataFrame acts in many ways like a two-dimensional array, and in other ways like a dictionary of Series structures sharing the same index. These analogies can be helpful to keep in mind as we explore data selection within this structure.
DataFrame as Dictionary
The first analogy we will consider is the DataFrame as a dictionary of related Series objects. The individual Series that make up the columns of the DataFrame can be accessed via dictionary-style indexing of the column name:
pokemon['Type 1']
Equivalently, we can use attribute-style access with simple string column names:
pokemon.HP
Though this is a useful shorthand, keep in mind that it does not work for all cases! For example: if the column names include whitespace (like 'Type 1'), are not strings, or if the column names conflict with methods of the DataFrame, this attribute-style access is not possible.
Like with the Series objects discussed earlier, this dictionary-style syntax can also be used to modify the object, in this case adding a new column:
# Compute ratio of Attack stat to Special Attack stat
pokemon['Attack Ratio'] = pokemon['Attack'] / pokemon['Sp. Atk']
Viewing Data, Statistics, Filtering
Attributes:
df.shape- tuple of (rows, columns)df.columns- list of column namesdf.index- row index infodf.dtypes- data type of each column
Functions:
df.head(n)- show first n rows (default 5)df.tail(n)- show last n rows (default 5)df.sample(n)- show random sample of n rowsdf.info()- summary of columns, non-null counts, data typesdf.describe()- numeric summary (mean, std, min, max)df.describe(include='all')- includes non-numeric columnsdf.count()- number of non-null values per columndf['col'].value_counts()- frequency counts for values in a columndf.sort_values('col')[:10]- top 10 after sortingdf.nlargest(5, 'col')- 5 largest values in coldf.nsmallest(5, 'col')- 5 smallest values in col
Aggregation with .groupby
- Average stats by primary type:
df.groupby('Type 1')[['Attack', 'Defense', 'Speed']].mean()Output: Shows mean Attack, Defense, and Speed for each Pokémon type (e.g., Fire, Water, Grass).
- Count of Pokémon by type:
df.groupby('Type 1').size().sort_values(ascending=False)Output: Number of Pokémon per primary type, sorted from most to least common.
- Average total stats by generation:
df['Total'] = df[['HP', 'Attack', 'Defense', 'Speed']].sum(axis=1) df.groupby('Generation')['Total'].mean()Output: Average combined stats per generation.
- Compare legendary vs. non-legendary averages:
df.groupby('Legendary')[['Attack', 'Defense', 'Speed']].mean()Output: two rows,
False(normal Pokémon) andTrue(legendary), with mean values for each stat.
Conditional Filtering
- Select Pokémon with HP greater than 100:
df[df['HP'] > 100] - Select Fire-type Pokémon:
df[df['Type 1'] == 'Fire'] - Select Pokémon that are both Fire and Flying type:
df[(df['Type 1'] == 'Fire') & (df['Type 2'] == 'Flying')] - Select Pokémon that are either Water or Ice type:
df[(df['Type 1'] == 'Water') | (df['Type 1'] == 'Ice')] - Select Pokémon with Attack above 120 and Defense below 60:
df[(df['Attack'] > 120) & (df['Defense'] < 60)] - Select Pokémon whose name contains “Mega”:
df[df['Name'].str.contains('Mega')] - Exclude Legendary Pokémon:
df[df['Legendary'] == False] # or equivalently df[~df['Legendary']] - Select Pokémon with Speed between 80 and 100:
df[(df['Speed'] >= 80) & (df['Speed'] <= 100)] - Select only Grass-type Pokémon that are not Legendary:
df[(df['Type 1'] == 'Grass') & (df['Legendary'] == False)] - Select top 5 Electric Pokémon with highest Attack:
df[df['Type 1'] == 'Electric'].nlargest(5, 'Attack')
Selecting Rows in DataFrames
Recall that a DataFrame acts in many ways like a two-dimensional array, and in other ways like a dictionary of Series structures sharing the same index. These analogies can be helpful to keep in mind as we explore data selection within this structure.
DataFrame as Two-Dimensional Array
As mentioned previously, we can also view the DataFrame as an enhanced two-dimensional array.
We can examine the raw underlying data array using the values attribute:
pokemon.values
Indexers: .loc & .iloc
When it comes to indexing of a DataFrame object, Pandas again uses the loc and iloc indexers mentioned earlier.
- Use
.ilocwhen you want to access data by position. - Use
.locwhen you want to access data by label (e.g., Pokémon names).
Using the iloc indexer, we can index the underlying array as if it were a simple NumPy array (using the implicit Python-style index), but the DataFrame index and column labels are maintained in the result:
# Read a specific location [R, C]
print(pokemon.iloc[100,1])
# Read several rows
print(pokemon.iloc[25:30])
# Read every row for a certain column
for index, row in pokemon.iterrows():
print(index, row['Name'])
Similarly, using the loc indexer we can index the underlying data in an array-like style but using the explicit index and column names:
grass_types = pokemon.loc[pokemon['Type 1'] == "Grass"]
print(grass_types)
Using String Indices
If you modify your DataFrame to use string indices, such as the Pokémon names, you will likely use .loc more frequently than .iloc. You first need to set the Pokémon names as the index:
poke = pokemon.set_index('Name', inplace=True)
Accessing a specific row and column:
# Example accessing Pikachu's type by name
print(poke.loc['Pikachu', 'Type 1'])
To read multiple rows using .loc, you need to specify a list of Pokémon names:
# Example accessing a range of Pokémon by their names
print(poke.loc[['Squirtle', 'Bulbasaur', 'Charmander']])
When iterating with .iterrows(), it automatically provides the index (now Pokémon names) along with the row:
# Iterate through each row, printing Name - Type
for index, row in poke.iterrows():
print(index, " - ", row['Type 1'])
⭐️ Glossary
Definitions
- Data Frame
- Data frames are multidimensional arrays taken from a larger dataset. They are used to implement specific data operations that may not need the entire dataset. (In pandas it is called
DataFrame) - Explicit Index
- Uses the values (numeric or non-numeric) set as the index. For example, if we set a column or row as the index then we can use values in the row or column as indices in different panda methods.
- Implicit Index
- Uses the location (numeric) of the indices, similar to the python style of indexing.
- Index
- An Index is a value that represents a position (address) in the
DataFrameorSeries. - Series
- A series is an array of related data values that share a connecting factor or property.
Keywords
-
import: Import lets programmers use packages, libraries or modules that have already been programmed. -
<DataFrame>[<string>]: return the series corresponding to the given column (). -
<DataFrame>[<list of strings>]: returns a given set of columns as aDataFrame. -
<DataFrame>[<series/list of Boolean>]: If the index in the given list isTruethen it returns the row from that same index in theDataFrame. -
<DataFrame>.loc[ ]: Uses explicit indexing to return aDataFramecontaining those indices and the values associated with them. -
<DataFrame>.loc[<string1>:<string2>]: This takes in a range of explicit indices and returns aDataFramecontaining those indices and the values associated with them. -
<DataFrame>.loc[<string>]: Uses an explicit index and return the row(s) for that index value. -
<DataFrame>.loc[<list/series of strings>]: Returns a newDataFramecontaining the labels given in the list of strings. -
<DataFrame>.iloc[ ]: Uses implicit indexing to return aDataFramecontaining those indices and the values associated with them. -
<DataFrame>.iloc[<index, range of indices>]: This takes in an implicit index (or a range of implicit indices) and returns aDataFramecontaining those indices and the values associated with them. -
<DataFrame>.set_index [<string)>]: Sets an existing column(s) with thename as the index of the ``DataFrame``. -
<DataFrame>.head(<numeric>): Returns the firstelement(s). If no parameter ( ) is set then it will return the first five elements. -
<pandas>.DataFrame(<data>): Used to create aDataFramewith the given data. -
<pandas>.read_csv(): Used to read a csv file into aDataFrame. -
<DataFrame>.set_index(<column>): Gets the values of the given column and sets them as indices. The output will be sorted in accending order based on the new indices. -
<pandas>.to_numeric(): Converts what is inside the parenthesis into neumeric values. -
<series>.str.startswith(<string>):.str.startswith()(in pandas) checks if a series contains a string(s) that starts with the given prarameter (), and returns a boolean value (True or False). -
<data frame>.sort_index(): Sorts the different objects in theDataFrame. By default, theDataFrameis sorted based on the first column in accending order.
Acknowledgement
Content on this page is adapted from How to Think Like a Data Scientist on Runestone Academy - Brad Miller, Jacqueline Boggs, and Jan Pearce and Python Data Science Handbook - Jake VanderPlas.